Large Language Models (LLMs)
LLMs generate coherent, contextually relevant text from a prompt. They summarize documents, extract structured data from unstructured text, and draft clinical, administrative, and educational content.
Real generative AI applications working in clinical and operational healthcare today — grounded in production deployments, not proof-of-concept demos.







Tell us the workflow you're evaluating. We'll map what's production-ready — reply within 24 hours.
Generative AI in healthcare almost always means large language models (LLMs) — systems that understand and generate natural language. Knowing what they are, and are not, is the foundation for any responsible deployment.

LLMs generate coherent, contextually relevant text from a prompt. They summarize documents, extract structured data from unstructured text, and draft clinical, administrative, and educational content.
GPT-4, Claude, and Gemini power most healthcare AI applications today. Azure OpenAI Service and Google Vertex AI are the common enterprise deployment paths for HIPAA BAA coverage.
LLMs are not reliable reasoning engines for novel clinical problems and cannot learn from patient interactions without retraining. Hallucination — plausible but factually incorrect content — remains a genuine risk that shapes where they deploy responsibly.
Safe applications cluster where AI drafts content a human reviews before use, or summarizes and extracts from existing documents rather than generating new clinical knowledge.
Six applications delivering consistent, measurable value in production deployments across clinical and operational healthcare in 2026.
The applications that work share design patterns. The ones that fail skip them.
The hype cycle has passed. These are the honest limitations clinical leaders need to understand before making deployment decisions.
Using an LLM to answer diagnostic or treatment questions at the point of care remains high-risk. Models can produce confidently wrong answers hard to distinguish from correct ones — exactly where hallucination risk is most dangerous.
AI agents taking actions in clinical systems without human review are not widely deployed in 2026. The technology is capable; validation frameworks for clinical safety are not yet mature for consequential actions.
LLMs have no access to live patient data unless it is provided in the prompt. Deployments that assume the model "knows" current patient status without structured retrieval are unreliable — RAG is not optional for patient-specific applications.
Foundation models cannot learn from specific patient interactions without retraining. Ongoing AI governance and periodic retraining are required infrastructure, not optional features.
The practical question is which model performs best on your specific use case — evaluated through testing, not vendor claims.
Book a Generative AI ConsultationFive steps that separate responsible deployments from the ones that generate headlines for the wrong reasons.

Define exactly what the AI will and will not do before evaluating models. Note generation, prior auth drafting, and data extraction each need different evaluation criteria — broad interfaces are where reliability degrades.

Design human review as a first-class workflow component — who reviews, at what point, with what authority to correct. Applications that work in production design this in; the ones that fail treat it as an afterthought.

Probe the system for failure modes before any clinical users see it — adversarial prompts, edge cases, dangerous outputs. Failures found in testing are far cheaper than those found in production with real patient consequences.

Production generative AI requires ongoing monitoring, drift detection, and periodic retraining as guidelines and regulations change. Budget AI governance as a recurring operational cost, not a one-time deployment expense.

Every component touching PHI needs BAA coverage — the foundation model API, the RAG vector database, and logging. Azure OpenAI, Vertex AI, and major vector database providers offer BAAs; confirm scope before data flows.
Every component of a healthcare generative AI stack that touches PHI is in scope. These are the frameworks governing responsible deployment in 2026.
BAAs required for every AI provider touching PHI — foundation model API, vector database, logging.
Access controls, encryption in transit and at rest, and audit logging for every PHI access — including AI-generated outputs.
Emerging frameworks for AI transparency, bias detection, and model accountability in clinical settings.
Clinical decision support AI may meet the FDA's Software as a Medical Device definition. Determine the regulatory pathway before architecture.
The integration standards that connect generative AI outputs back into the clinical record and downstream workflows.
Models must be validated across demographic groups before clinical deployment — bias in training data becomes bias in clinical output.
Every part of the healthcare ecosystem is evaluating generative AI. The organizations making the most progress started with narrow, high-evidence use cases and built governance infrastructure before expanding scope.
Organizations getting real value from generative AI in healthcare start with a narrowly scoped use case — ambient documentation, prior auth drafting, structured extraction — and build human review and AI governance before expanding. Our healthcare AI engineers help health systems, payers, and digital health companies evaluate, architect, and deploy generative AI responsibly.
Book a Free Consultation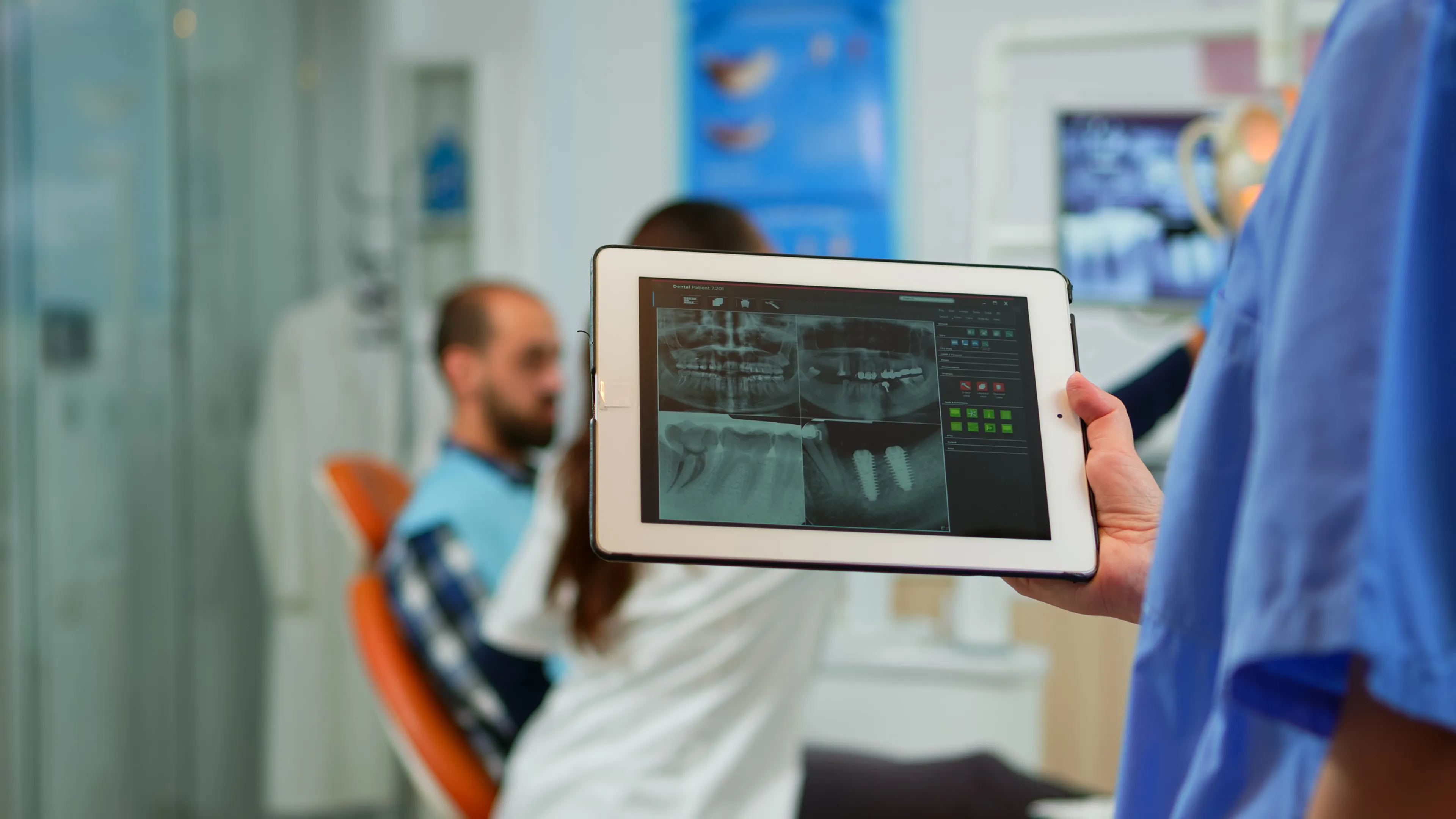
100 Fastest Growth Companies
Global Spring Winner
Top App Development Company
AWS Partner Network
Google Cloud Partner
Highly Rated on Trustpilot
Verified Agency
Top App Development Company
ASSOCHAM Member
The primary strategy is human review before any AI-generated content is used clinically — clinicians review notes before signature, staff review prior auth drafts before submission. Teams add RAG to ground responses in verified clinical reference content and red-team before deployment to surface failure modes. RAG and human review together address most hallucination risk in well-scoped applications.
General-purpose LLMs like GPT-4 and Claude carry significant medical knowledge from broad training data; healthcare-specific models are fine-tuned on clinical data for specialized tasks. In practice, well-prompted general-purpose LLMs often perform comparably on many clinical NLP tasks, though the gap varies by task. Evaluate through testing on your actual use case, not by model category.